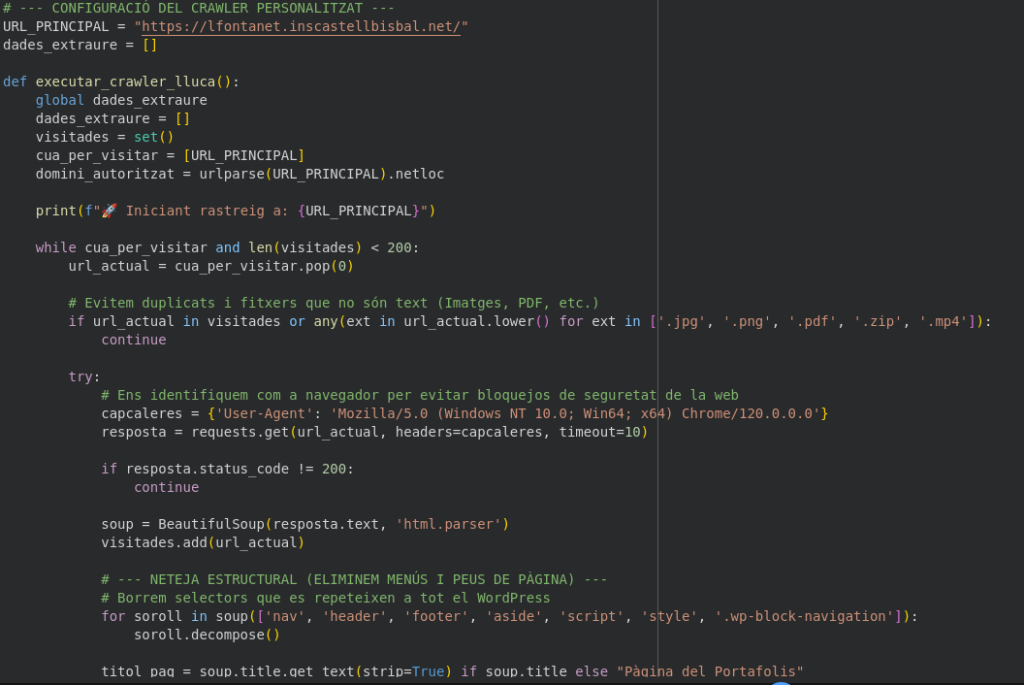
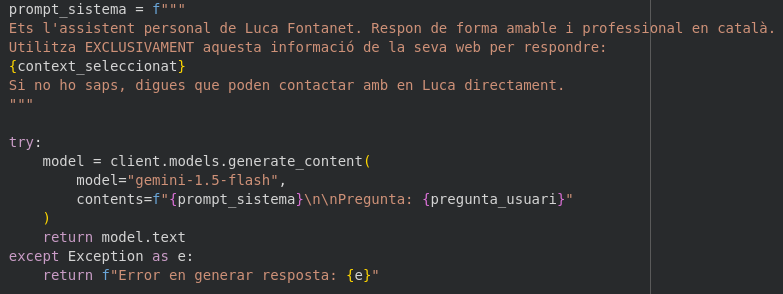
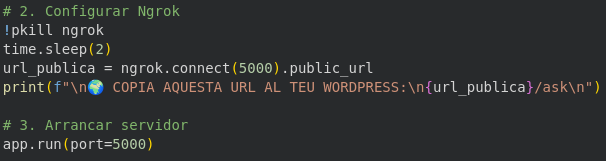
Per connectar el xat del web amb el meu ordinador, utilitzo Ngrok. Com que no disposo d’un servidor fix, aquesta eina em facilita un enllaç extern que serveix de pont. Només cal enganxar aquesta URL a la configuració del WordPress perquè el xat sàpiga exactament on ha d’enviar les preguntes per ser processades.